NeuroLabyrinth - a platform for parallel learning of agents
AI & Machine Learning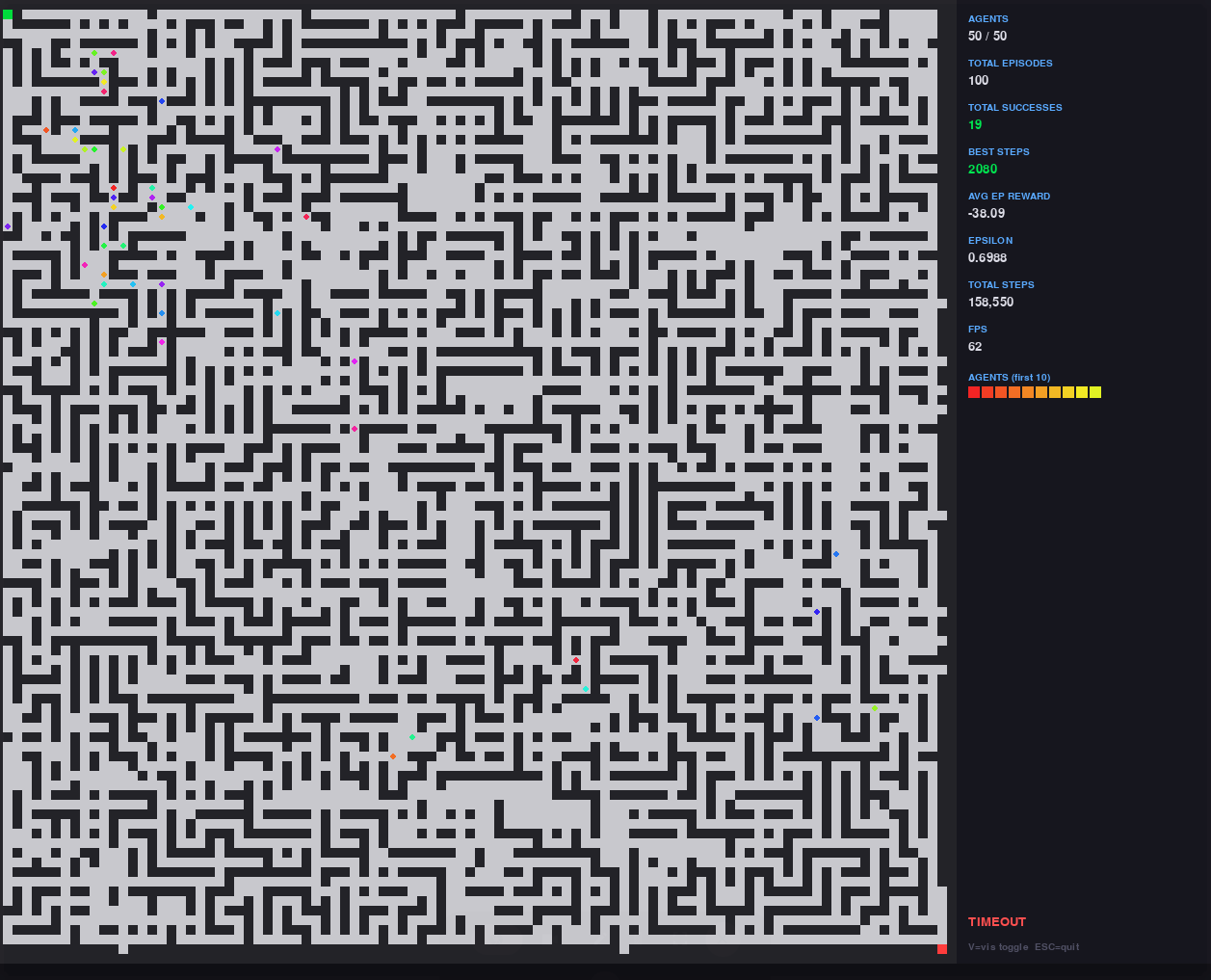
This is a high-performance reinforcement learning system built around the multi-agent environment Maze RL, optimized for real computational loads and scaling.
The project implements a fully vectorized simulation, where dozens of agents are trained simultaneously in the same environment. The architecture is specifically designed to move away from the classic single-agent approach and replace it with parallel learning in a shared environment, which radically increases the efficiency of computational resource usage.
Each agent operates independently, but within a unified environment, allowing for the modeling of competitive and collective behavior simultaneously. The system supports batch processing of observations and actions, where all agents undergo a forward pass in a single operation, without N separate model calls. This provides a significant performance boost and makes the system suitable for scaling to hundreds of agents.
The environment is built on procedural generation of complex mazes with controlled structural entropy: cycles, traps, dead ends, false paths, and narrow corridors. This creates a rich learning space where the agent cannot rely on trivial strategies and is forced to develop a robust navigation policy.
The system supports dynamic visualization on Pygame, where all agents are displayed in real-time, including their positions, progress, and aggregated learning statistics. If necessary, the visualization can be turned off, and the system switches to a high-speed headless mode, achieving thousands of agent-steps per second on the CPU.
Training is based on a DQN architecture with a replay buffer, target network, and epsilon decay, adapted for multi-agent mode. Instead of the classic episodic cycle, a streaming step training is used, where model updates occur continuously as experience is received from all agents.
As a result, it is a system that serves both as a research platform and an engineering tool: it demonstrates the behavior of complex RL agents under conditions of dense parallelization, allows for testing scaling strategies, and visually observes collective learning in real-time.
Essentially, it is not just an agent simulator, but a full-fledged environment for developing and stress-testing reinforcement learning algorithms in multi-agent scenarios with high interaction density.
The project implements a fully vectorized simulation, where dozens of agents are trained simultaneously in the same environment. The architecture is specifically designed to move away from the classic single-agent approach and replace it with parallel learning in a shared environment, which radically increases the efficiency of computational resource usage.
Each agent operates independently, but within a unified environment, allowing for the modeling of competitive and collective behavior simultaneously. The system supports batch processing of observations and actions, where all agents undergo a forward pass in a single operation, without N separate model calls. This provides a significant performance boost and makes the system suitable for scaling to hundreds of agents.
The environment is built on procedural generation of complex mazes with controlled structural entropy: cycles, traps, dead ends, false paths, and narrow corridors. This creates a rich learning space where the agent cannot rely on trivial strategies and is forced to develop a robust navigation policy.
The system supports dynamic visualization on Pygame, where all agents are displayed in real-time, including their positions, progress, and aggregated learning statistics. If necessary, the visualization can be turned off, and the system switches to a high-speed headless mode, achieving thousands of agent-steps per second on the CPU.
Training is based on a DQN architecture with a replay buffer, target network, and epsilon decay, adapted for multi-agent mode. Instead of the classic episodic cycle, a streaming step training is used, where model updates occur continuously as experience is received from all agents.
As a result, it is a system that serves both as a research platform and an engineering tool: it demonstrates the behavior of complex RL agents under conditions of dense parallelization, allows for testing scaling strategies, and visually observes collective learning in real-time.
Essentially, it is not just an agent simulator, but a full-fledged environment for developing and stress-testing reinforcement learning algorithms in multi-agent scenarios with high interaction density.