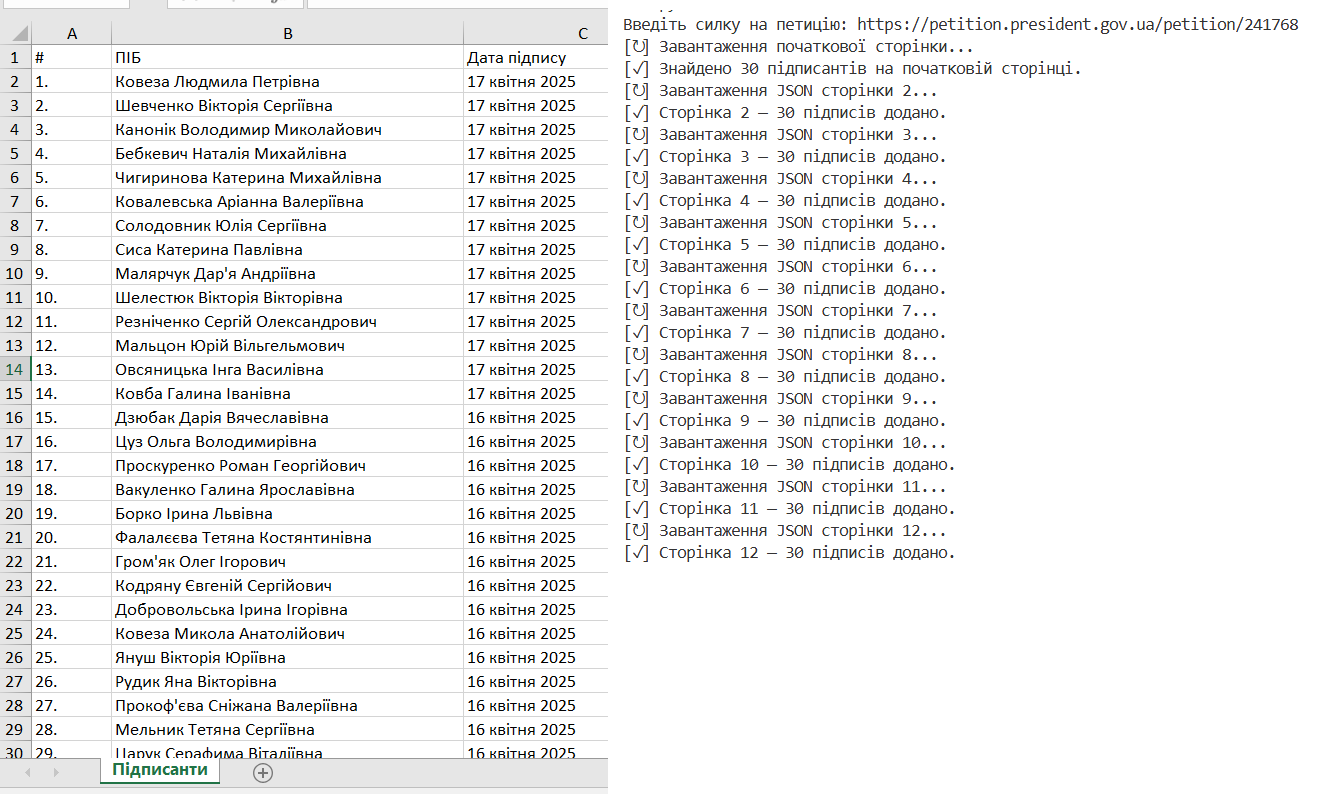
This parser automates the collection of information about signatories of electronic petitions from the official website of the President of Ukraine. It accepts a link to a specific petition and sequentially gathers data from all pages of signatures, including the name, surname, and signing date of each user.
The parser works in two stages: first, it loads and parses the static HTML of the first page of the petition, where part of the signatories are displayed, and then it dynamically retrieves additional pages via AJAX requests to the API in JSON format. The obtained data is processed and stored in Excel (.xlsx) format with incremental updates to the file after each page, ensuring reliable operation even if the process is interrupted.
Technologies used: Python, libraries requests (HTTP requests), BeautifulSoup (HTML parsing), openpyxl (working with Excel), regular expressions (extracting petition ID), as well as basic JSON processing mechanisms. The parser is designed for stable operation with large volumes of data and takes into account the features of dynamic content loading.
The parser works in two stages: first, it loads and parses the static HTML of the first page of the petition, where part of the signatories are displayed, and then it dynamically retrieves additional pages via AJAX requests to the API in JSON format. The obtained data is processed and stored in Excel (.xlsx) format with incremental updates to the file after each page, ensuring reliable operation even if the process is interrupted.
Technologies used: Python, libraries requests (HTTP requests), BeautifulSoup (HTML parsing), openpyxl (working with Excel), regular expressions (extracting petition ID), as well as basic JSON processing mechanisms. The parser is designed for stable operation with large volumes of data and takes into account the features of dynamic content loading.