Parsing a protected SPA website, Bypassing Cloudflare and anti-bot systems
Data Parsing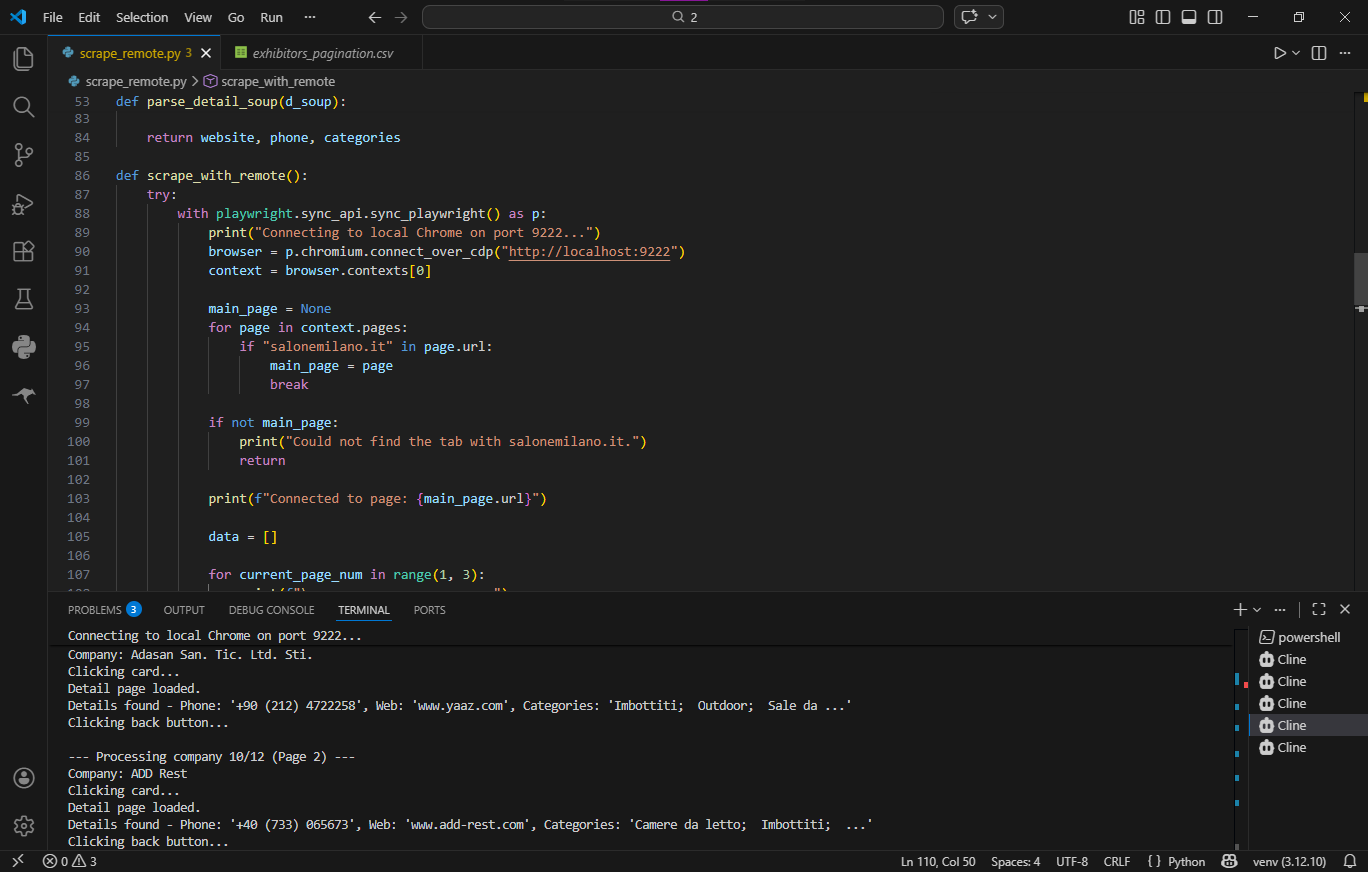
Objective: Gather 100% accurate data on over 1000 exhibitors (name, country, booth number, hidden emails and phone numbers, categories) from the official Salone del Mobile website.
Main challenges:
Aggressive anti-bot protection (Cloudflare): Standard requests (requests/httpx) returned 403 Forbidden. Regular headless browsers (Selenium, Playwright) and even frameworks like undetected-chromedriver were instantly blocked.
Complex SPA architecture (React / Next.js): The website did not have standard HTML links. All navigation occurred exclusively through React event handlers (onClick), making traditional URL collection impossible. Additionally, contact details were hidden in non-semantic tags (for example,
Main challenges:
Aggressive anti-bot protection (Cloudflare): Standard requests (requests/httpx) returned 403 Forbidden. Regular headless browsers (Selenium, Playwright) and even frameworks like undetected-chromedriver were instantly blocked.
Complex SPA architecture (React / Next.js): The website did not have standard HTML links. All navigation occurred exclusively through React event handlers (onClick), making traditional URL collection impossible. Additionally, contact details were hidden in non-semantic tags (for example,
).
My solution:
To achieve perfect accuracy and bypass protection, I developed a custom hybrid approach:
Connection via Chrome DevTools Protocol (CDP): Instead of launching a new instance of an automated browser, my script used Playwright to connect to an already running, "live" session of Google Chrome (http://localhost:9222). This provided a 100% "trust factor" of a legitimate user (along with real cookies, history, and Canvas fingerprints). Cloudflare was bypassed without any solved captchas.
Intelligent navigation: The script visually mimicked human behavior — intercepting dynamic locators, physically clicking the mouse to trigger React states, and using the site's internal router to return to the list while maintaining pagination.
HTML parsing: The captured page state was processed through BeautifulSoup and complex regular expressions (Regex) for accurate extraction of "broken" or poorly formatted links and phone numbers.
Technologies used:
Python 3.12
Playwright (Sync API): interaction with the DOM and connection via CDP.
BeautifulSoup4 & Regex: precise searching and data extraction.
Pandas: structuring and exporting data into clean CSV (UTF-8 with BOM) and Excel.
Result:
The script autonomously collected and perfectly formatted data for over 1200 companies. The created architecture allows for scalable parsing without the risk of getting banned by IP.
My solution:
To achieve perfect accuracy and bypass protection, I developed a custom hybrid approach:
Connection via Chrome DevTools Protocol (CDP): Instead of launching a new instance of an automated browser, my script used Playwright to connect to an already running, "live" session of Google Chrome (http://localhost:9222). This provided a 100% "trust factor" of a legitimate user (along with real cookies, history, and Canvas fingerprints). Cloudflare was bypassed without any solved captchas.
Intelligent navigation: The script visually mimicked human behavior — intercepting dynamic locators, physically clicking the mouse to trigger React states, and using the site's internal router to return to the list while maintaining pagination.
HTML parsing: The captured page state was processed through BeautifulSoup and complex regular expressions (Regex) for accurate extraction of "broken" or poorly formatted links and phone numbers.
Technologies used:
Python 3.12
Playwright (Sync API): interaction with the DOM and connection via CDP.
BeautifulSoup4 & Regex: precise searching and data extraction.
Pandas: structuring and exporting data into clean CSV (UTF-8 with BOM) and Excel.
Result:
The script autonomously collected and perfectly formatted data for over 1200 companies. The created architecture allows for scalable parsing without the risk of getting banned by IP.