Smart Chunker: preparation of documents for RAG and vector databases
AI & Machine Learning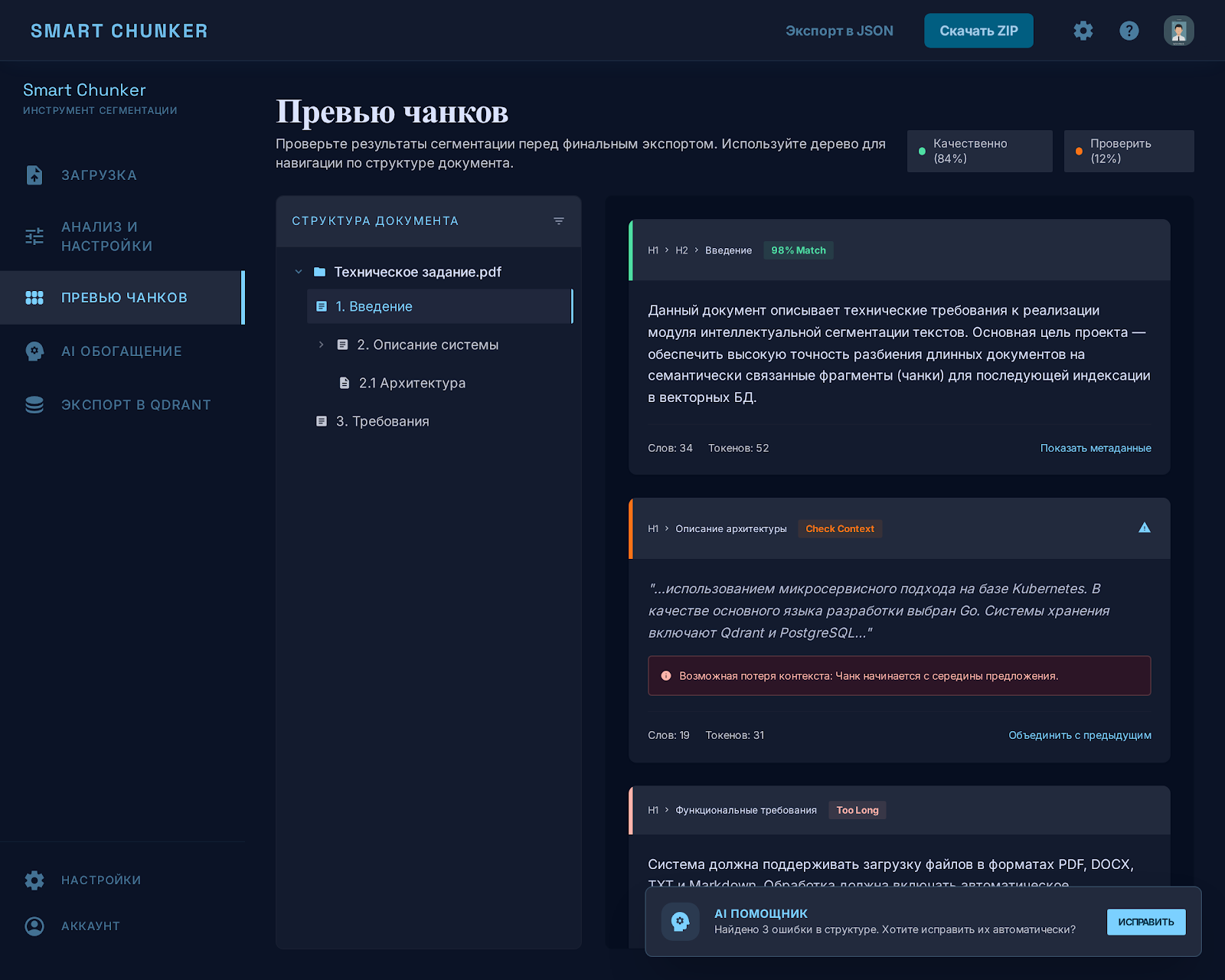
The AI agent responds as well as its context is prepared. To prepare a large knowledge base for RAG, I created Smart Chunker: it cuts Markdown into meaningful chunks, highlights problem areas, and loads the prepared data into a vector database. Before searching, the knowledge is normalized, without broken fragments and duplicates.
What's inside:
- Deterministic core: parsing Markdown into an H1-H3 header tree and 7 chunking rules, without overlap.
- Automatic size selection of chunks by iterating through a grid of up to 2500 combinations.
- Quality control is visible in the interface: problematic chunks are highlighted, and the system suggests what to fix.
- AI layer: the architect proposes a metadata schema, the agent enriches chunks with packages, and the result undergoes validation.
- Loading into Qdrant: dense vectors via embeddings, sparse through local BM25, updates via Smart Match. 20 API endpoints.
API keys live only in the browser and are not stored on the server. Basic chunking works even without external models.
#Python #RAG #Qdrant #FastAPI #AI #VectorDB #LLM #NLP #VanillaJS #OpenAI #Anthropic #BM25 #SSE
What's inside:
- Deterministic core: parsing Markdown into an H1-H3 header tree and 7 chunking rules, without overlap.
- Automatic size selection of chunks by iterating through a grid of up to 2500 combinations.
- Quality control is visible in the interface: problematic chunks are highlighted, and the system suggests what to fix.
- AI layer: the architect proposes a metadata schema, the agent enriches chunks with packages, and the result undergoes validation.
- Loading into Qdrant: dense vectors via embeddings, sparse through local BM25, updates via Smart Match. 20 API endpoints.
API keys live only in the browser and are not stored on the server. Basic chunking works even without external models.
#Python #RAG #Qdrant #FastAPI #AI #VectorDB #LLM #NLP #VanillaJS #OpenAI #Anthropic #BM25 #SSE