Web Scraping and Data Processing System
Data Parsing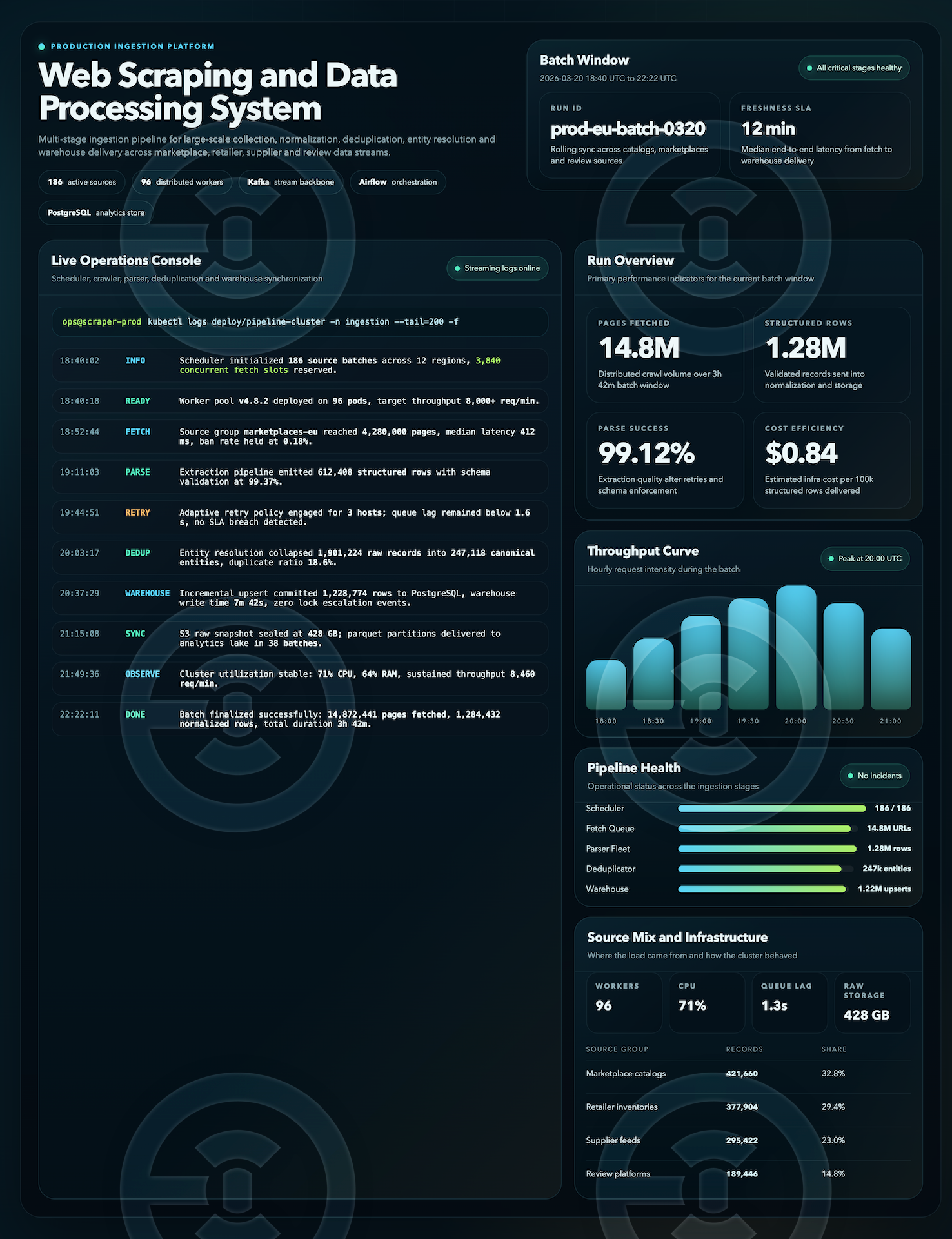
Development of a web scraping and data processing system for multi-stage collection, normalization, deduplication, and preparation of large data volumes for analytics and internal business workflows.
The project included designing an ingestion pipeline for large-scale data collection from multiple source types, followed by queue-based processing, entity normalization, schema validation, deduplication, and preparation for warehouse delivery. Special attention was given to batch stability, data quality, and observability across all critical stages of the pipeline.
Implemented project logic includes:
— multi-stage data collection and processing pipeline
— distributed source handling and batch execution
— record normalization and deduplication
— latency, throughput, and processing quality monitoring
— preparation of structured data for warehouse / analytics use cases
— pipeline health, logs, and operational metrics visibility
Stack and approach:
web scraping, data processing, batch pipelines, normalization, deduplication, PostgreSQL, Kafka, Airflow, warehouse-oriented ingestion, operational monitoring.
Result:
a structured large-scale data collection and processing system focused on stability, data quality, pipeline transparency, and convenient future scaling.
The project included designing an ingestion pipeline for large-scale data collection from multiple source types, followed by queue-based processing, entity normalization, schema validation, deduplication, and preparation for warehouse delivery. Special attention was given to batch stability, data quality, and observability across all critical stages of the pipeline.
Implemented project logic includes:
— multi-stage data collection and processing pipeline
— distributed source handling and batch execution
— record normalization and deduplication
— latency, throughput, and processing quality monitoring
— preparation of structured data for warehouse / analytics use cases
— pipeline health, logs, and operational metrics visibility
Stack and approach:
web scraping, data processing, batch pipelines, normalization, deduplication, PostgreSQL, Kafka, Airflow, warehouse-oriented ingestion, operational monitoring.
Result:
a structured large-scale data collection and processing system focused on stability, data quality, pipeline transparency, and convenient future scaling.